Seq2Seq Language Model
Date: 23.06.01
Writer: 9tailwolf : doryeon514@gm.gist.ac.kr
Introduction
Existing method of NLP has a problem with fixed input/output size. But LSTM is free with input/output size. By Labeling SOS,(Start Of String) and EOS, (End Of String). By using above characteristic, We can improve Language Model.
Seq2Seq
Seq2Seq is a Language Model that works with double RNN(LSTM) as Encoder and Decoder. Below is a architecture of Seq2Seq.
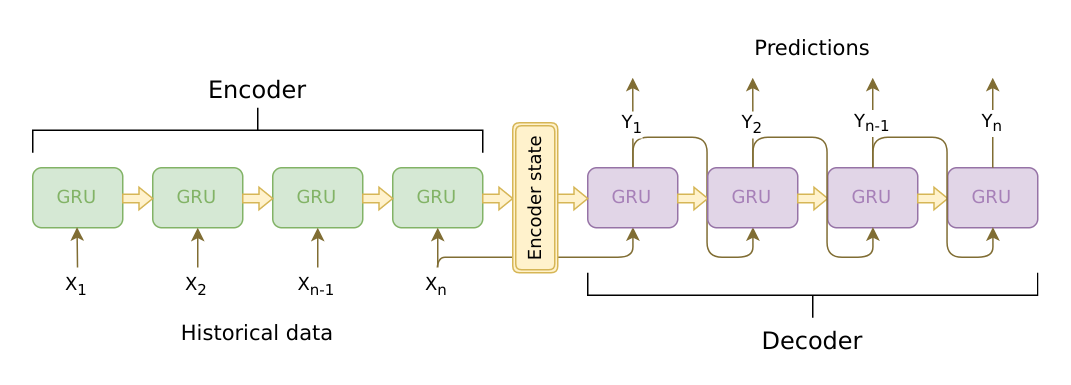
Encoder
At Encoder Layer, we use \(x_{t}\) as input, and it can computate hidden layer \(h_{t} = f(x_{t},h_{t-1})\). By this way, Seq2Seq consist encoder state until \(x_{t}\) reached EOS.
Decoder
At Decoder Layer, we use \(y_{t}\) as input(at first layer, we use \(x_{l}\), \(l\) is a last data of input.), and it can computate hidden layer \(h_{t} = f(y_{t},h_{t-1})\). Output is used recursively.