BERT Language Model
Date: 23.06.29
Writer: 9tailwolf : doryeon514@gm.gist.ac.kr
Introduction
BERT(Bidirectional Encoder Representations from Transformers) is a useful language model for universal DL model. It is a pre-training method of language model. Performance is improved by using BERT for any model. We will find out how this BERT works.
Embedding for BERT
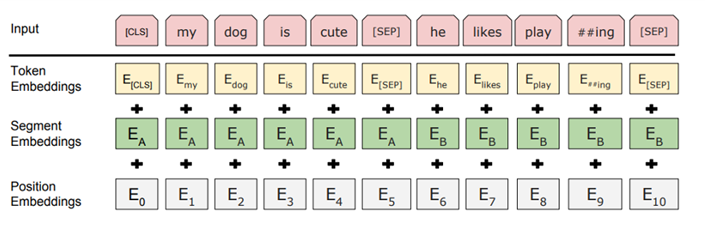
1. Embedding
We need an Embedding that tokenizes the sentence. There is a special tokens, \(E_{CLS}\) which informs start of input, \(E_{SEP}\) which informs seperating point. In this layer, Word Piece is applied. Word Piece is a method that divide sub-word that usually using in word. By this way, understanding of sentence can improve effectivly.
2. Segement Embedding
At this layer, we can divide sentences. This way, we can make input of sentences.
3. Position Embedding
It is same as Transformer.
Encoder
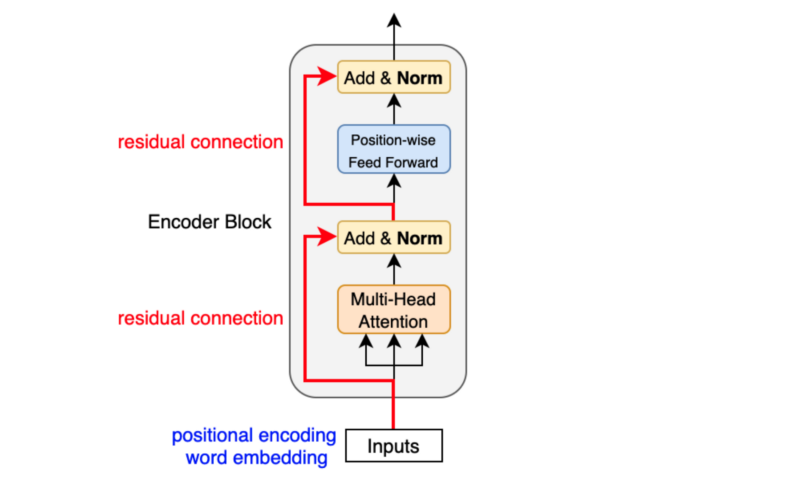
When we apply Embedding, then we can use Encoder. The encoder is a simmilar as encoder of transformer. Continous of transformer encoder is a encoder of BERT.
There is a two types of BERT. One is BERT base, and the other one is BERT large. BERT base has a 12 transformer encoder blocks, 768 dimension hidden layer, and 12 head of self-attention. BERT large has a 24 transformer encoder blocks, 1024 dimension hidden layer, and 16 head of self-attention.
Pre-Training of BERT
There is a two types of BERT pre-training task.
1. Masked Language Model
Masked Language Model(MLM) is a task that estimate randomly masked token. The ratio of masked word is 15%. 80% of the masked word become mask, 10% of the word become random word, and remind 10% of the word maintain.
2. Next Sentence Prediction
Next Sentence Prediction(NSP) is trained by giving two sentences and guessing whether or not this sentence is a continuation sentence. 50% of the training data is continous sentence and otherwise, isn’t.